ResonIA: mapas de conversación para humanos, chatbots y voicebots
Una conversación no falla solo cuando alguien se queja. Falla antes: en un bucle, una retirada, una transferencia sin contexto, una respuesta defensiva o un bot que vuelve a preguntar lo que ya sabe. ResonIA nace para hacer visible ese comportamiento.
Durante mucho tiempo hemos tratado las conversaciones como texto final: se transcriben, se resumen, se etiquetan y se archivan. Pero una conversación no es solo contenido. Es una secuencia de turnos, energía, silencios, repeticiones, reparaciones y cambios de dirección.
Eso aplica a una reunión interna, a una llamada de soporte, a una conversación de ventas, a un chat entre cliente y agente, a un chatbot de texto y a un voicebot telefónico. El problema de fondo es el mismo: necesitamos entender dónde se rompe la interacción, con evidencia suficiente para mejorarla.
La tesis
ResonIA no intenta diagnosticar personas ni declarar intenciones ocultas. Convierte conversaciones humanas y conversaciones mediadas por IA en mapas temporales de comportamiento observable: intensidad, fricción, bucles, reparación, handoff, contexto perdido y momentos críticos.
Las empresas ya no hablan solo con personas
Una empresa moderna conversa por muchas capas: equipos humanos en reuniones, agentes de soporte, comerciales, chatbots de texto, voicebots telefónicos, formularios conversacionales, CRM summaries y eventos de sistema. Cada capa puede ayudar, pero también puede romper el hilo.
Conversaciones humanas
Reuniones, soporte, ventas, mediación interna o conversaciones difíciles donde importa detectar escalada, retirada, escucha y reparación.
Chatbots de texto
Flujos donde el usuario reformula la misma intención, el bot responde fuera de contexto o el prompt no sabe cuándo escalar.
Voicebots
Llamadas donde además del contenido aparecen tono, pausas, interrupciones, latencia, frustración y handoff humano tardío.
Del resumen al mapa
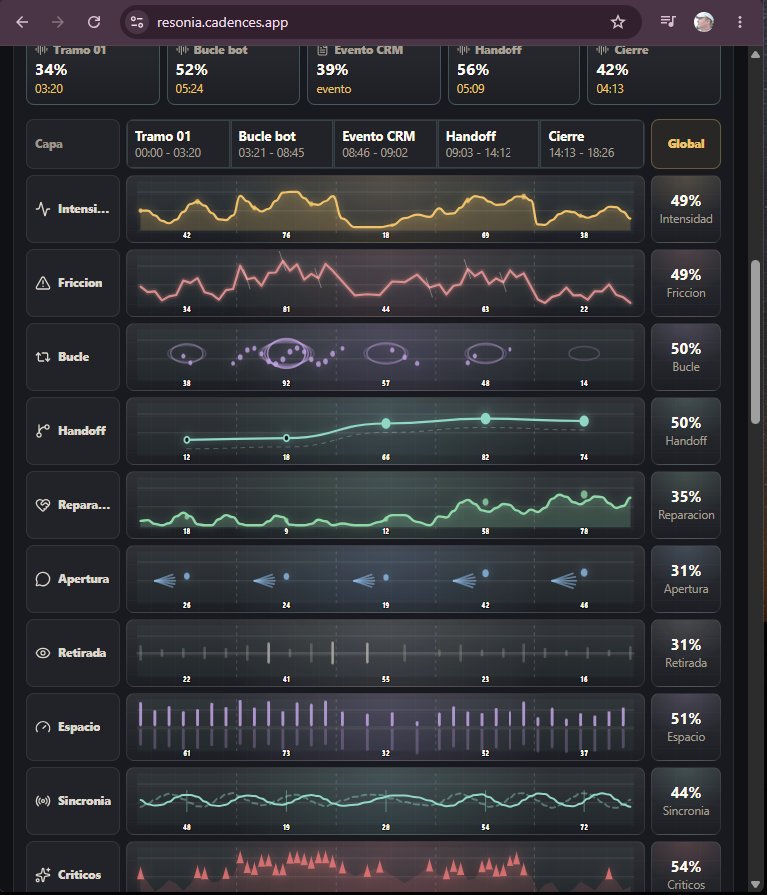
Un resumen responde a "qué se dijo". Un mapa conversacional responde a preguntas más operativas: dónde se repitió la intención, dónde subió la fricción, dónde el sistema perdió contexto, dónde alguien intentó reparar, dónde convenía transferir a humano y qué tramo merece revisión primero.
Representación conceptual: cada fila es una capa observable y cada tramo conserva evidencia revisable.
El mismo motor, distintos contextos
| Contexto | Que observa ResonIA | Que mejora |
|---|---|---|
| Equipo humano | Interrupciones, dominancia, retirada, ventanas de reparación, temas que elevan tensión. | Feedback, retrospectivas, liderazgo, cultura de conversación y seguimiento de acuerdos. |
| Soporte y ventas | Fricción, esfuerzo del cliente, claridad de respuesta, intentos de cierre, escalada. | QA de llamadas, entrenamiento, playbooks y priorización de revisiones. |
| Chatbot de texto | Reformulaciones, loops, intenciones no cubiertas, respuestas fuera de contexto. | Prompts, intents, retrieval, fallback y reglas de transferencia. |
| Voicebot | Bucle vocal, frustración, silencio, latencia, handoff tardío y pérdida de datos ya aportados. | Diseño conversacional, memoria de transferencia, prompts de agente y rutas de escalado. |
Una conversación compuesta, no un archivo aislado
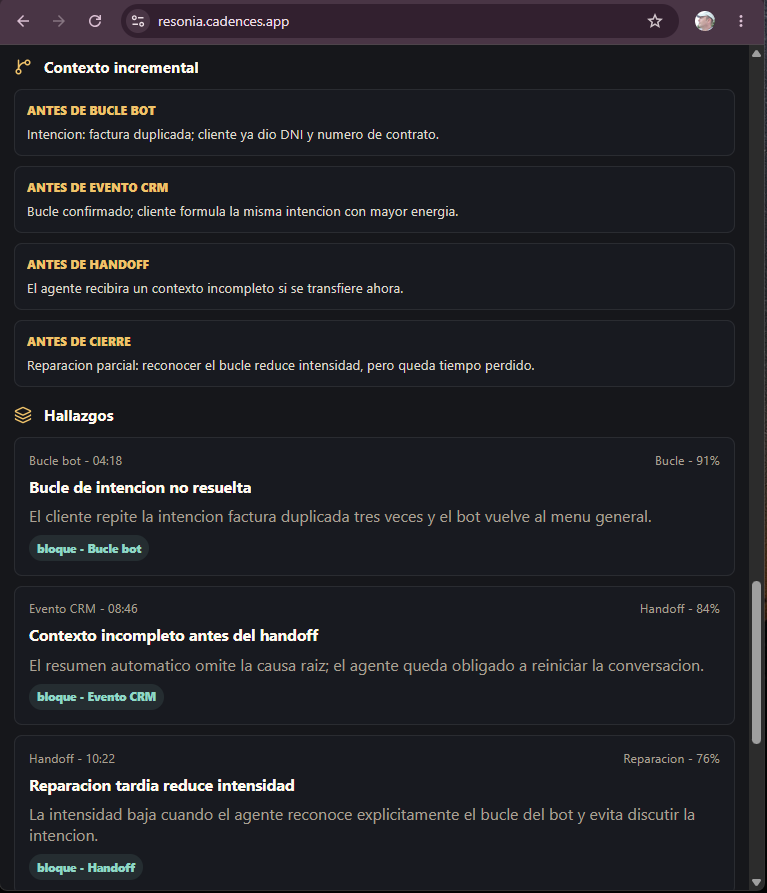
En la práctica, una conversación no siempre vive en un solo audio. Puede empezar con una llamada, seguir con un resumen CRM, continuar con mensajes, volver a voz y terminar con un agente humano. Por eso ResonIA trabaja con montajes: bloques de audio, texto y eventos en orden temporal.
Cada bloque se analiza localmente, pero el contexto validado se arrastra hacia delante. El segundo audio no empieza desde cero si antes hubo un mensaje importante.
Qué hay construido hoy
En las últimas semanas ResonIA ha pasado de prototipo de UI a un estudio funcional con análisis real, no maquetas. El studio corre como SPA en resonia.cadences.app y todo el cómputo pesado vive en el navegador. Estas son las piezas que ya están dentro:
Análisis acústico real en el navegador
Pipeline propio sin red ni descarga de modelos: re-muestreo a 16 kHz, ventanas de 32 ms con hop de 12 ms, RMS, ZCR, F0 con YIN (70-450 Hz) con corrección de octava, centroide / flujo / planitud / rolloff85 espectral, sonoridad A-weighted y VAD multi-criterio con hangover. La energía y la prosodia son medidas, no inventadas.
Whisper local vía Transformers.js
Transcripción 100% en el equipo del usuario sobre WebGPU, con alineamiento palabra a palabra contra la señal acústica. Cada palabra hereda su F0 medio, su rango tonal y su energía, lo que permite resaltar tramos enfáticos con base prosódica, no por adivinación.
Carriles de hablante con k-means heurístico
V1 sin huellas vocales y sin enviar nada a servidor: clustering local sobre vector de tono, energía, ritmo y rango pitch por chunk, con selección de k por silueta, suavizado y umbral mínimo de coherencia. Etiquetas pensadas como navegación de evidencia, no como identidad biométrica.
10 capas semánticas con cita literal
intensity,
discord,
loop,
repair,
handoff,
openness,
avoidance,
dominance,
synchrony,
critical.
DeepSeek a través del proxy de Cadences (sin API keys del usuario), con JSON estricto y cada hallazgo respaldado por una frase literal del transcript. Si no hay cita, el hallazgo se descarta.
Heurística + IA, no IA sola
Sobre cada bloque corren dos motores en paralelo: el heurístico (rápido, transparente, basado en léxico con coincidencia por palabra completa para evitar falsos positivos del tipo "cancelar" disparando por aparecer dentro de "encantado") y el semántico IA (DeepSeek con prosodia inyectada en el prompt). Los hallazgos se muestran fusionados pero marcados por origen, para que cualquier evaluador pueda separar qué viene de regla y qué viene de inferencia.
Conversaciones compuestas, ya en producción
El estudio acepta cargas reales: audios de WhatsApp (incluyendo el contenedor de iPhone, que rompe a la mitad de los players), MP3, WAV, OGG, y bloques de texto plano para representar el hilo escrito que rodeó a las llamadas. El orden temporal se mantiene, el contexto se arrastra y la batería de pruebas incrementales — desde un audio aislado hasta montajes mixtos con eventos de sistema — corre como red de seguridad antes de cada release.
| Entrada | Procesamiento | Dónde corre |
|---|---|---|
| Audio (mp3, wav, ogg, m4a iPhone) | Decode → re-sample 16 kHz → DSP → Whisper → alineamiento → diarización. | Navegador (WebGPU + WASM) |
| Texto / evento CRM | Normalización + carry-forward hacia bloques posteriores. | Navegador |
| Análisis semántico | Prompt con transcript + prosodia → JSON con 10 capas + cita literal. | DeepSeek vía proxy Cadences |
| Heatmap temporal | Tiras RADIA-style + evidencia clickable por tramo. | Navegador (render local) |
El audio no sale del equipo
El decodificado, el DSP, el Whisper y la diarización ocurren íntegramente en el navegador. A la nube solo viaja, cuando el usuario lo solicita, el transcript ya generado junto a las métricas de prosodia agregadas — no el audio. Para los usos donde ni siquiera eso es aceptable (sanidad, RRHH internos, conversaciones sensibles), las capas heurísticas locales son funcionales por sí solas y dan ya un mapa revisable sin LLM.
No medir personas. Medir interacciones.
La frontera importa. ResonIA no debe decir "esta persona manipula", "este empleado es conflictivo" o "la IA sabe lo que siente el cliente". Ese lenguaje es peligroso y falso. Lo correcto es hablar de señales observables y evidencia temporal.
Evitar
- Diagnosticar personalidad o intenciones ocultas.
- Usar el informe para vigilar o culpar.
- Convertir hipótesis en veredictos.
- Separar una frase de su contexto temporal.
Preferir
- Mostrar tramo, evidencia y capa activada.
- Hablar de patrones observables.
- Permitir confirmar, descartar o comentar hallazgos.
- Separar mejora de proceso de juicio sobre personas.
De RADIA a ResonIA
RADIA nos enseñó que una información compleja se entiende mejor como un espacio navegable: capas, calor, hallazgos y recorridos guiados. ResonIA aplica esa misma idea a conversaciones. Donde RADIA tiene cortes, volumen y hallazgos clínicos revisables, ResonIA tiene turnos, tramos, contexto incremental y hallazgos conversacionales revisables.
La oportunidad
El mercado ya tiene transcriptores, resúmenes y dashboards de contact center. Falta una capa de observabilidad conversacional que explique cómo se comporta una interacción, por qué se degrada y qué se puede mejorar: una reunión humana, un chat de soporte, un bot de texto o un voicebot.
Pruébalo
El estudio está abierto: sube un audio (puede ser tuyo, de WhatsApp, de una llamada con consentimiento) y compruébalo. Verás las 10 capas, los hallazgos con cita literal y el mapa temporal en pocos segundos. El audio no sale de tu navegador. La meta no es automatizar conclusiones, sino dar al equipo una interfaz donde cada hallazgo se pueda revisar contra la evidencia.
Abrir ResonIA