WhatsApp Agent: IA Local-First con Fallback Cloud
Cómo construimos un agente WhatsApp que escucha notas de voz, mira imágenes, genera audio y dibujos, embebe en local con
EmbeddingGemma 300M y decide entre LM Studio, WebLLM en WebGPU o proxy cloud — sin que el usuario tenga que pensar en ello. Y cómo encaja con
resonia.cadences.app
y
vilasenvento.cadences.app
para formar el stack conversacional completo de Cadences.

Gonzalo Monzón
· Fundador & CTO

Casi todos los agentes "IA para WhatsApp" del mercado son lo mismo: un servidor centralizado al que envías el número de teléfono y la conversación, y que decide por ti — con tu cuenta, en su data center, leyendo tus mensajes. Es cómodo, pero rompe el modelo mental que importa: WhatsApp es privado, tu agente también debería serlo.
El planteamiento: una app Electron que abre WhatsApp Web en su propio Chromium controlado por Playwright, persiste todo en SQLite local, y monta una pila de IA local-first con cinco servicios — LLM, embeddings, STT, TTS, ITT y TTI — donde lo local se prefiere y la nube es fallback, no requisito.
Cinco servicios de IA, dos modos de ejecución
El agente tiene cinco capacidades multimedia y cada una elige independientemente si corre en local o en la nube. La regla es la misma para todas: si hay recurso local, se usa; si no, fallback a la nube, sin pedir API keys al usuario.
| Capacidad | Local primero | Fallback nube | Trigger automático |
|---|---|---|---|
| LLM | LM Studio :1234/v1 · WebLLM (MLC) en WebGPU | DeepSeek · Groq · Gemini · Cloudflare AI | Cada mensaje entrante |
| Embeddings | EmbeddingGemma-300M ONNX q8 (768 dim) | — (siempre local) | Indexado de chats y docs |
| STT | (roadmap) Whisper ONNX in-process | Cloudflare Whisper · Groq · OpenAI | Nota de voz entrante |
| TTS | — (calidad insuficiente local) | Cloudflare MeloTTS (gratis) | Usuario pide "dímelo con voz" |
| ITT (visión) | — (modelos VLM aún muy pesados) | Gemini · GPT-4o · Cloudflare LLaVA | Imagen entrante |
| TTI | — (no factible en CPU del usuario) | Cloudflare Flux (gratis) con seed | "haz una imagen de..." |
Para los servicios que sí tienen variante local plausible (LLM y embeddings), la decisión se toma por petición. Para los demás, vamos al proxy de Cadences, que abstrae cinco proveedores detrás de una sola URL. Esto resuelve el problema más aburrido de cualquier agente multimedia: no pedirle al usuario seis API keys distintas para que su asistente funcione.
LM Studio, WebLLM o proxy: la decisión en 4 ramas
El cliente LLM detecta cada 30 segundos si hay un endpoint compatible OpenAI corriendo en localhost:1234. Si lo hay, lista los modelos y elige el primero. Si no, va al proxy cloud con el modelo por defecto del proveedor seleccionado. WebLLM es un caso aparte: corre dentro del proceso renderer del Electron, sobre WebGPU, y los modelos viven en Cache Storage tras la primera descarga.
// 1. ¿Hay LM Studio escuchando? (cache 30s)
const detected = await this.detect(); // GET :1234/v1/models
if (provider === 'local' && detected.ok) {
return await _chatViaLocal(messages, detected.models[0]);
}
// 2. WebLLM corre en el renderer (IPC bridge)
if (provider === 'webllm') {
return await _chatViaWebllm(messages, model);
}
// 3. Proxy cloud — y aquí el truco anti-foot-gun:
// si por error nos llega un model MLC para una llamada cloud,
// lo cambiamos al default del provider en lugar de fallar.
if (model && isWebllmModel(model)) {
model = getProvider(provider).defaultModel;
}
return await _chatViaCadences({ messages, model, provider });
El proxy cloud vive en cadences.pages.dev/api/ai-providers/chat. Recibe un provider + model, resuelve la API key del lado servidor (jamás baja al cliente) y devuelve el chat completion estándar OpenAI. Los seis proveedores soportados son los mismos que usa el resto del ecosistema:
| Provider | Modelo por defecto | Cuándo brilla |
|---|---|---|
| DeepSeek | deepseek-chat | Default. Calidad/€ imbatible en español |
| Groq | llama-3.3-70b-versatile | Latencia: ~250 ms primera token |
| Gemini | gemini-2.0-flash | Contexto largo + multimodal |
| Cloudflare AI | @cf/meta/llama-3.1-8b-instruct-fp8-fast | Tier gratuito generoso |
| LM Studio | Auto-detectado /v1/models | Privacidad absoluta + sin Internet |
| WebLLM | Qwen3.5-2B-q4f16_1-MLC | Cero instalación, corre en WebGPU |
STT, TTS, ITT y TTI: enriquecimiento automático del mensaje
La idea operativa es que el LLM nunca debe verse limitado por el formato del mensaje entrante. Si llega una nota de voz, se transcribe y entra al prompt como texto. Si llega una foto, se describe y entra como texto. El LLM responde una sola vez, pero el agente puede contestar con audio o imagen si el usuario lo pide.
STT — Transcripción automática de notas de voz
El messageWatcher detecta type === 'audio', extrae el blob OGG/Opus desde el DOM, lo manda al proxy de Cadences que enruta a Cloudflare Whisper (1500 req/día gratis) o Groq Whisper si el primero está saturado. La transcripción se inyecta en el evento message como transcription.text, y el autoReplyService la usa como query sin que ninguna otra capa se entere de que era audio.
ITT — Análisis de imágenes entrantes
Mismo patrón con imágenes: extracción de blob, base64, llamada a Gemini Vision (preferido) o LLaVA-1.5 de Cloudflare como fallback. Prompt fijo: "Describe esta imagen en detalle. Si contiene texto, transcríbelo. Si es un documento, ticket o factura, extrae los datos relevantes." Esto resuelve sin extra coste el caso "te envío la factura por foto" — habitual en pymes y autónomos que llevan WhatsApp como CRM real.
TTS — Respuesta por audio cuando se pide
Un detector regex en el mensaje entrante busca "dímelo con voz", "mándame un audio", "responde por audio". Si dispara, el LLM genera la respuesta normalmente y después MeloTTS (Cloudflare) sintetiza el MP3. Se encolan dos mensajes: texto primero (por accesibilidad y log), audio después. El flag es local al scope de la petición — no hay estado compartido entre contactos, así que dos personas pidiendo audio simultáneamente no se pisan.
TTI — Generación de imágenes con memoria de seed
Detectamos peticiones del tipo "hazme una imagen de...", "dibuja...", "genera un logo de...". Llamada a Cloudflare Flux vía proxy, con seed opcional. Truco clave: tras enviar la imagen, el agente guarda el {prompt, seed, model, aspectRatio} en un Map<phone, ...> con ventana de 30 min. Si el usuario contesta "modifícala", "igual pero más oscura", "estilo cómic" o "ahora con un perro", se detecta como modificación, se combina con el prompt original y se reusa la seed. Es la diferencia entre "una imagen aleatoria" y "una conversación visual".
EmbeddingGemma-300M sobre ONNX: 768 dimensiones, 0 dependencias cloud
Aquí es donde el "local-first" deja de ser slogan y se vuelve infraestructura. El agente carga onnx-community/embeddinggemma-300m-ONNX quantizado a 8 bits (~338 MB en disco, ~1.4 GB en RAM) usando @huggingface/transformers. Es el mismo runtime que usaría Transformers.js en el navegador, pero corriendo en Node dentro del Electron, lo que permite usar SIMD nativo en CPU sin tener que pelear con WASM threading.
Latencia real
Cold load (primera llamada): ~7s mientras se mapea el modelo a RAM. Warm: ~26 ms por frase. Suficiente para indexar conversaciones en background sin bloquear UI.
Persistencia
Vectores guardados como BLOB Float32 en SQLite. 3072 bytes por embedding. Una conversación de 10k mensajes ocupa ~30 MB de vectores — perfectamente manejable sin sqlite-vec.
Búsqueda híbrida
BM25 (FTS5 de SQLite) + KNN coseno in-memory, fusionados con Reciprocal Rank Fusion. ~15 ms para sweeps de hasta 50k chunks. Sin GPU, sin Pinecone, sin Qdrant.
Privacidad real
Tras la primera descarga del modelo, el indexado de tus chats nunca sale del equipo. Funciona en avión. El backend de Cadences ignora por completo qué contenido tienes.
Esto alimenta un sistema de contexto en cuatro capas que el contextBuilder ensambla antes de cada llamada al LLM:
| Capa | Contenido | Presupuesto |
|---|---|---|
| L0 — Identidad | Quién es el agente, beliefs, vocabulario, estilo | ~1200 tok |
| L0.5 — Persona | Tono concreto: casual / formal / welcome / short | ~200 tok |
| L1 — Memoria contacto | Top-N chunks por importancia × recencia | ~400 tok |
| L1-Cross | Historia 1↔1 de remitentes activos del grupo | ~400 tok |
| L3 — RAG híbrido | BM25 + KNN sobre toda la base, RRF | ~600 tok |
Las 10 capas de ResonIA, también en texto
ResonIA es nuestro estudio de QA conductual para llamadas: subes un audio y obtienes un mapa temporal de 10 capas semánticas — Intensidad, Fricción, Bucle, Handoff, Reparación, Apertura, Retirada, Dominancia, Sincronía, Críticos — más hallazgos como "Bucle de intención no resuelta" o "Contexto incompleto antes del handoff". Sin diagnosticar a las personas, sin juzgar: mostrando evidencia para que el equipo decida.
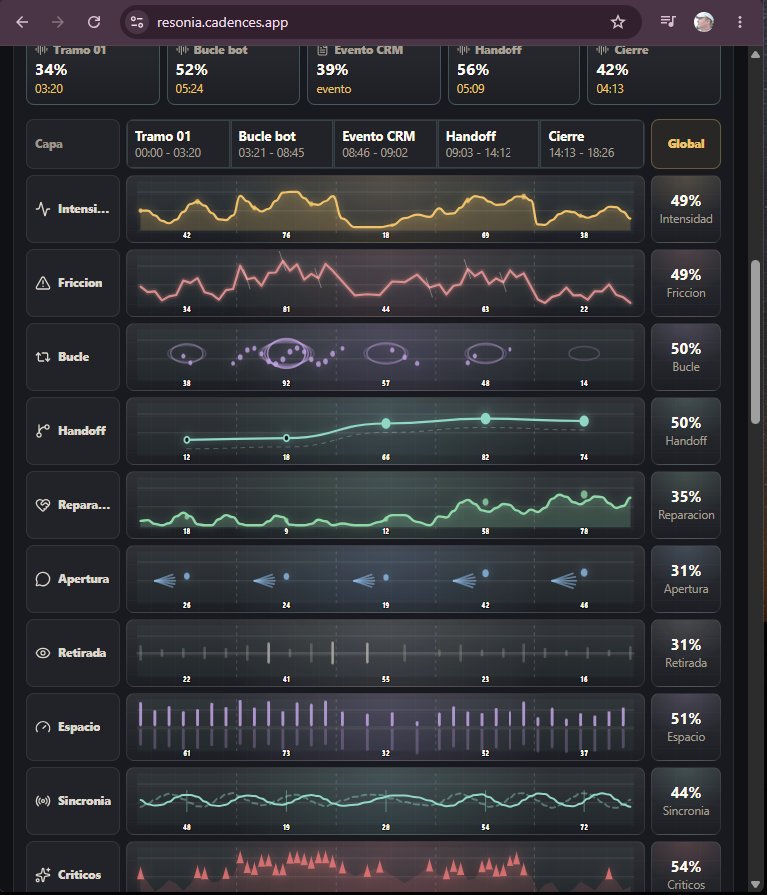
En el WhatsApp Agent reutilizamos la misma tipología de 10 capas, pero adaptada a texto y sin LLM por mensaje (sería caro). Una capa heurística — conversationClimate.js — corre regex y léxico sobre el mensaje actual, puntúa cada capa con un peso, y si la dominante supera un threshold (≥14) inyecta una directiva al prompt antes del LLM:
// Mensaje del usuario detectado como capa 'loop' (repetición)
// Score: 18, dominante
"El cliente está repitiendo la misma intención por tercera vez."
"Reconoce explícitamente que has entendido qué quiere antes"
"de proponer cualquier acción. No vuelvas al menú general."Es deliberadamente conservador: no pretende sustituir el análisis de ResonIA (que sí usa prosodia, diarización y LLM dedicado), sino dar al agente un instinto básico para no caer en los patrones que ResonIA ya identifica como destructivos en llamadas. La misma teoría conversacional, dos puntos de aplicación: ResonIA observa post-hoc, el WhatsApp Agent actúa en tiempo real.
Vila Sen Vento, ResonIA y WhatsApp Agent: una misma idea, tres canales
vilasenvento.cadences.app es la vitrina pública del modelo. Una tienda demo de despensa artesanal gallega cerca de Santiago, pensada como prueba de concepto comercial: asistente de texto en streaming (SSE) con DeepSeek V4 + function calling (5 tools), asistente de voz con ElevenLabs Conversational AI, y handoff voz↔chat (si cuelgas la llamada, el chat retoma la conversación con todo el contexto). RAG sobre catálogo, memoria entre sesiones, OTP + Twilio para callbacks programados.
Las tres piezas resuelven el mismo problema desde ángulos distintos:
Vila Sen Vento — el cliente nuevo te encuentra en la web
Astro estático en Cloudflare Pages, chat SSE + voz ElevenLabs. Optimizado para descubrimiento (SEO, Open Graph) y conversión inmediata. Lo que un visitante anónimo prueba en su primera sesión.
WhatsApp Agent — el cliente conocido te escribe por WhatsApp
Electron en el escritorio del dueño/equipo, memoria local persistente. El mismo modelo conversacional que en Vila Sen Vento, ahora con historia real del contacto, capacidades multimedia completas y privacidad absoluta de la base de datos.
ResonIA — el equipo aprende qué funciona y qué no
React + Whisper local + DeepSeek. Subes la grabación de una llamada (voicebot, humana o mixta) y obtienes el mapa de 10 capas + hallazgos accionables. Cierra el ciclo: lo que ResonIA detecta en las llamadas mejora los prompts del WhatsApp Agent y del chat de Vila Sen Vento.
Tres cosas que aprendimos construyéndolo
1. Local-first no es "todo en local"
Forzar STT/TTS/TTI/ITT en local hoy es una mala decisión: los modelos buenos no caben en el equipo del usuario medio, y los que caben dan resultados pobres. La línea correcta es: lo que se puede correr local con calidad aceptable (LLM ligero, embeddings) se hace local; lo demás va al proxy. Y el usuario nunca ve la diferencia.
2. El proxy resuelve el problema de las API keys
Pedirle a un autónomo que configure cinco API keys para que su WhatsApp responda solo es no haber entendido el producto. El proxy de Cadences abstrae DeepSeek, Groq, Gemini, Cloudflare AI, MeloTTS, Whisper, Flux y Vision detrás de una URL única, con resolución de claves en backend. El usuario configura cero claves y todo funciona.
3. La memoria es lo que convierte un chatbot en un agente
Sin embeddings persistentes, sin memoria de seed para iterar imágenes, sin tipología conversacional para no caer en bucles — tienes un chatbot. Con ellos, tienes algo que recuerda al cliente, sabe qué le ha enviado antes, y entiende que "modifícala más oscura" se refiere a la imagen anterior y no requiere generar otra desde cero. La diferencia no se ve en el demo. Se ve en el uso real, a los tres días.
¿Cómo lo pruebas?
Vila Sen Vento está abierto en vilasenvento.cadences.app — chatea o haz una llamada. ResonIA en resonia.cadences.app acepta tus audios privados (procesamiento local, no se suben). El WhatsApp Agent es la app Electron descargable desde cadences.app, pensada para autónomos y pymes que quieren convertir su WhatsApp en un canal con IA real sin perder la propiedad de los datos.